Il y a quelques temps j’ai posté un premier article sur le remplacement de Redis par PostgreSQL qui, s’il est toujours intéressant, n’est malheureusement pas très optimisé. En effet, j’ai fait quelques erreurs et, plutôt que de corriger l’article précédent, j’ai préféré le conserver afin de faire un nouvel article dédié à la correction de ces erreurs.
Dans le présent article, j’utilise exclusivement PostgreSQL 18. Cette version apportant des gains de performance significatifs dans certains domaines, vous pourriez potentiellement constater des différences en utilisant une version différente.
Erreur 1 : sous-estimer les valeurs par défaut #
Dans toutes les tables que j’ai précédemment modélisé, seul le champ
created_at avait une valeur par défaut. C’est vraiment dommage car ça m’a fait
passer à côté de choses vraiment intéressantes. Reprenons un premier modèle
naïf :
CREATE TABLE tokens_v1 (
id uuid
PRIMARY KEY
DEFAULT gen_random_uuid(),
created_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp,
expire_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp + interval '1 hour',
CHECK (created_at <= expire_at)
);L’identifiant peut bien entendu avoir une valeur par défaut, ici c’est la
fonction gen_random_uuid() qui se charge de générer un nouvel UUIDv4. Depuis
PostgreSQL 18, il est possible d’utiliser les fonctions uuidv4() et uuidv7()
pour respectivement générer des UUID v4 et v7.
Pour la date d’expiration, il est possible de simplement ajouter un interval au timestamp actuel. Personnellement j’apprécie beaucoup syntaxe humainement très lisible.
Ainsi, il nous est possible d’ajouter une nouvelle valeur sans rien n’avoir à générer côté client, tout est géré par PostgreSQL :
INSERT INTO tokens_v1 DEFAULT VALUES;Généralement on souhaite immédiatement utiliser les valeurs générées, par
exemple pour les afficher ou les placer dans un cookie. Afin d’éviter des
allez-retour inutiles avec la base de données, il est possible d’utiliser
RETURNING afin que l’INSERT se comporte comme un SELECT :
INSERT INTO tokens_v1
DEFAULT VALUES
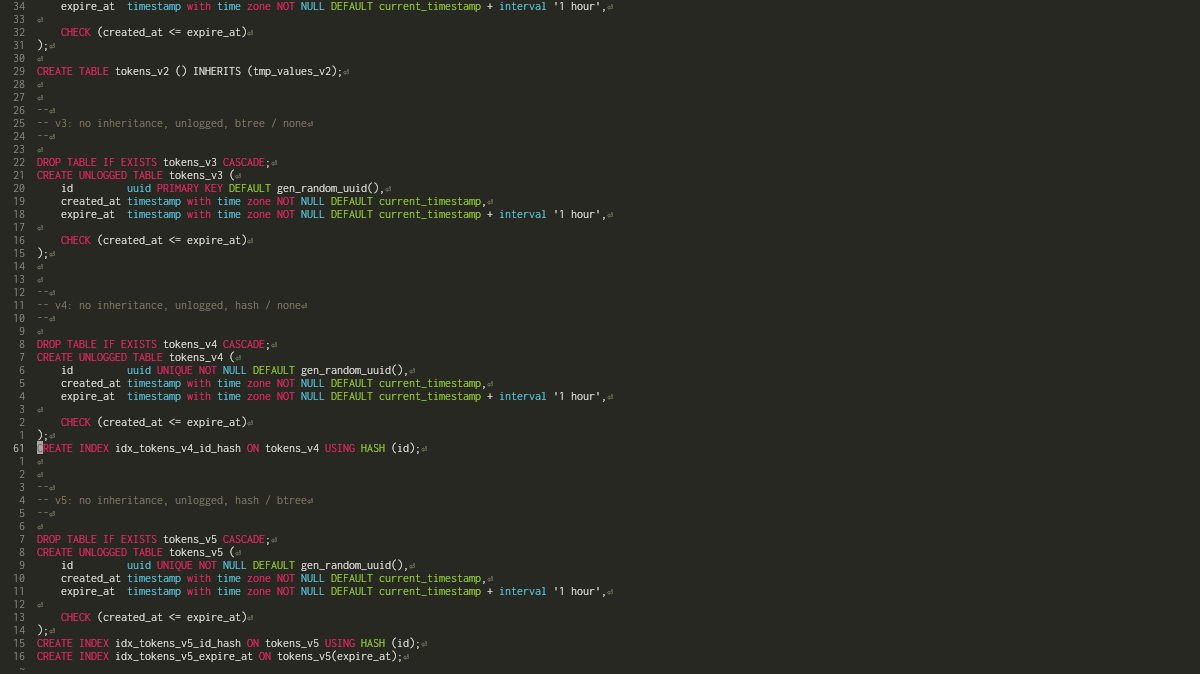
RETURNING id, created_at, expire_at;Erreur 2 : l’héritage #
En vrai, l’héritage de tables n’est pas une bonne idée, notamment parce qu’il présente un piège assez terrible : les indexes ne sont pas hérités. Et si on n’indexe pas l’identifiant, il va être très coûteux de le récupérer.
Notons qu’il est possible de continuer à utiliser l’héritage de manière efficace en créant l’index sur la bonne table, mais désormais je préfère éviter totalement l’héritage.
Afin de bien se rendre compte de la chose, comparons la version naïve du début de l’article (v1) avec sa version utilisant l’héritage sans avoir créé l’index (v2) :
CREATE TABLE tmp_values_v2 (
id uuid
PRIMARY KEY
DEFAULT gen_random_uuid(),
created_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp,
expire_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp + interval '1 hour',
CHECK (created_at <= expire_at)
);
CREATE TABLE tokens_v2 () INHERITS (tmp_values_v2);Afin de tester sur une table de bonne taille, j’ai ajouté 25 millions d’entrées. Comme ça vous ne viendrez pas me dire que c’est juste pour pour un projet qui n’a pas plus que « 3 gus dans un garage ».
EXPLAIN ANALYZE
SELECT *
FROM tokens_v1
WHERE
id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'
AND expire_at > current_timestamp;+------------------------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|------------------------------------------------------------------------------------------------------------------------------|
| Index Scan using tokens_v1_pkey on tokens_v1 (cost=0.56..8.59 rows=1 width=32) (actual time=0.025..0.027 rows=1.00 loops=1) |
| Index Cond: (id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'::uuid) |
| Filter: (expire_at > CURRENT_TIMESTAMP) |
| Index Searches: 1 |
| Buffers: shared hit=5 |
| Planning Time: 0.095 ms |
| Execution Time: 0.043 ms |
+------------------------------------------------------------------------------------------------------------------------------+
EXPLAIN 7
Time: 0.003sEXPLAIN ANALYZE
SELECT *
FROM tokens_v2
WHERE
id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'
AND expire_at > current_timestamp;+-------------------------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|-------------------------------------------------------------------------------------------------------------------------------|
| Gather (cost=1000.00..367131.15 rows=1 width=32) (actual time=357.629..360.085 rows=0.00 loops=1) |
| Workers Planned: 2 |
| Workers Launched: 2 |
| Buffers: shared hit=4252 read=179596 |
| -> Parallel Seq Scan on tokens_v2 (cost=0.00..366131.05 rows=1 width=32) (actual time=348.479..348.479 rows=0.00 loops=3) |
| Filter: ((id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'::uuid) AND (expire_at > CURRENT_TIMESTAMP)) |
| Rows Removed by Filter: 8333333 |
| Buffers: shared hit=4252 read=179596 |
| Planning Time: 0.068 ms |
| JIT: |
| Functions: 6 |
| Options: Inlining false, Optimization false, Expressions true, Deforming true |
| Timing: Generation 0.340 ms (Deform 0.112 ms), Inlining 0.000 ms, Optimization 0.293 ms, Emission 6.292 ms, Total 6.925 ms |
| Execution Time: 360.302 ms |
+-------------------------------------------------------------------------------------------------------------------------------+
EXPLAIN 14
Time: 0.363sOui, l’absence d’index a totalement démoli les performances. Quand la v1
s’exécute en 0,043 ms, celle avec l’héritage (donc sans index), met plus de
360 ms. La plan d’exécution de la requête est très clair : sur la v1 PostgreSQL
utilise l’index pour rapidement trouver la valeur (Index Scan avec un filtre
sur expire_at), alors que sur la v2 PostgreSQL est obligé de parcourir toutes
les données de la table avec un Parallel Seq Scan réparti sur plusieurs fils
d’exécution.
En conséquent, la durée d’exécution de cette seconde implémentation dépends de la taille de la table. Sur 25 millions d’entrées, la sanction est lourde. Sur 5 millions je reste dans les 100 ms, ce qui est cohérent avec les résultats de l’article précédent.
Erreur 3 : utiliser le mauvais type d’index #
Par défaut, PostgreSQL utile un arbre B pour gérer ses indexes. Si ce type d’index est générique et très performant pour la très grande majorité des cas, il existe cependant d’autres types d’index plus spécialisés. Compte tenu du fait que nous n’avons besoin que de vérifier une égalité stricte pour l’identifiant, un index basé sur une fonction de hachage peut nous intéresser.
Afin de comparer, créons deux nouvelles versions utilisant UNLOGGED TABLE :
une v3 avec un arbre B (automatique avec PRIMARY KEY) et une v4 avec une
fonction de hachage (on remplace PRIMARY KEY par UNIQUE et NOT NULL puis
on ajoute ensuite manuellement l’index) :
CREATE UNLOGGED TABLE tokens_v3 (
id uuid
PRIMARY KEY
DEFAULT gen_random_uuid(),
created_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp,
expire_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp + interval '1 hour',
CHECK (created_at <= expire_at)
);
CREATE UNLOGGED TABLE tokens_v4 (
id uuid
UNIQUE
NOT NULL
DEFAULT gen_random_uuid(),
created_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp,
expire_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp + interval '1 hour',
CHECK (created_at <= expire_at)
);
CREATE INDEX idx_tokens_v4_id_hash ON tokens_v4 USING HASH (id);Voyons ce que ça donne niveau performance :
EXPLAIN ANALYZE
SELECT *
FROM tokens_v3
WHERE
id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'
AND expire_at > current_timestamp;+------------------------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|------------------------------------------------------------------------------------------------------------------------------|
| Index Scan using tokens_v3_pkey on tokens_v3 (cost=0.56..8.59 rows=1 width=32) (actual time=0.020..0.021 rows=0.00 loops=1) |
| Index Cond: (id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'::uuid) |
| Filter: (expire_at > CURRENT_TIMESTAMP) |
| Index Searches: 1 |
| Buffers: shared hit=4 |
| Planning Time: 0.091 ms |
| Execution Time: 0.035 ms |
+------------------------------------------------------------------------------------------------------------------------------+
EXPLAIN 7
Time: 0.003sDéjà c’est une bonne nouvelle, utiliser une UNLOGGED TABLE améliore un peu
les performances. C’est carrément moins que l’absence d’index causé par
l’héritage, mais c’est toujours bon à prendre.
Et donc la même chose mais avec un type d’index différent :
EXPLAIN ANALYZE
SELECT *
FROM tokens_v4
WHERE
id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'
AND expire_at > current_timestamp;+-------------------------------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|-------------------------------------------------------------------------------------------------------------------------------------|
| Index Scan using idx_tokens_v4_id_hash on tokens_v4 (cost=0.00..8.02 rows=1 width=32) (actual time=0.010..0.011 rows=0.00 loops=1) |
| Index Cond: (id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'::uuid) |
| Filter: (expire_at > CURRENT_TIMESTAMP) |
| Index Searches: 1 |
| Buffers: shared hit=1 |
| Planning Time: 0.090 ms |
| Execution Time: 0.024 ms |
+-------------------------------------------------------------------------------------------------------------------------------------+
EXPLAIN 7
Time: 0.002sSi le planificateur de requête n’a pas prévu d’amélioration significative, en pratique il y a tout de même une légère amélioration en terme de performance. Il arrive en effet que l’estimation ne soit pas bonne, d’où l’utilité de mesurer sur une requête réellement lancée.
Erreur bonus : ajouter des indexes inutiles #
Les indexes c’est super bien, ça permet de significativement améliorer la
performance nos requêtes, alors mettons-en sur tous les champs qui sont utilisés
dans les clauses WHERE. Ici il en manque donc un sur le champ expire_at,
alors créons donc une v5 qui y ajoute un index basé sur un arbre B qui, dans ce
cas, est le plus pertinent :
CREATE UNLOGGED TABLE tokens_v5 (
id uuid
UNIQUE
NOT NULL
DEFAULT gen_random_uuid(),
created_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp,
expire_at timestamp with time zone
NOT NULL
DEFAULT current_timestamp + interval '1 hour',
CHECK (created_at <= expire_at)
);
CREATE INDEX idx_tokens_v5_id_hash
ON tokens_v5
USING HASH (id);
CREATE INDEX idx_tokens_v5_expire_at
ON tokens_v5(expire_at);EXPLAIN ANALYZE
SELECT *
FROM tokens_v5
WHERE
id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'
AND expire_at > current_timestamp;+-------------------------------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|-------------------------------------------------------------------------------------------------------------------------------------|
| Index Scan using idx_tokens_v5_id_hash on tokens_v5 (cost=0.00..8.02 rows=1 width=32) (actual time=0.006..0.006 rows=0.00 loops=1) |
| Index Cond: (id = '7dbc731e-4c97-4f1d-a70e-812da29f0ab8'::uuid) |
| Filter: (expire_at > CURRENT_TIMESTAMP) |
| Index Searches: 1 |
| Buffers: shared hit=1 |
| Planning: |
| Buffers: shared hit=4 |
| Planning Time: 0.124 ms |
| Execution Time: 0.020 ms |
+-------------------------------------------------------------------------------------------------------------------------------------+
EXPLAIN 9
Time: 0.002sDans le cas présent ajouter un index n’a pas permis de vraiment améliorer
les performances qui sont déjà excellentes. D’ailleurs, en y réfléchissant
bien c’est normal : toute la différence se fait sur la capacité à trouver
l’identifiant. Une fois que ce dernier est trouvé, la seconde clause WHERE ne
sert qu’à vérifier s’il n’est pas périmé, ce qui n’a pas besoin d’un index.
En revanche, ce qu’a fait notre nouvel index c’est prendre de la place sur le disque pour rien . Observons donc la taille de nos indexes pour les v3 et v5 :
SELECT
pg_size_pretty(pg_relation_size('tokens_v3_pkey')) AS v3_id_btree,
pg_size_pretty(pg_relation_size('idx_tokens_v5_id_hash')) AS v5_id_hash,
pg_size_pretty(pg_relation_size('idx_tokens_v5_expire_at')) AS v5_expire_at_btree;+-------------+------------+--------------------+
| v3_id_btree | v5_id_hash | v5_expire_at_btree |
|-------------+------------+--------------------|
| 1006 MB | 777 MB | 663 MB |
+-------------+------------+--------------------+
SELECT 1
Time: 0.003sSur de une table de grande taille, la taille d’un index n’est pas forcément négligeable. Créer des indexes inutiles nous fait donc perdre de l’espace disque pour rien et, en plus, dégrade légèrement les performances d’insertion.
Nous observons également que l’index basé sur une fonction de hachage prend, dans ce cas précis, un peu moins de place que celui basé sur un arbre B. Sur les petites tables ça peut être l’inverse, donc comme toujours pensez à mesurer ce qui se passe dans votre cas précis.
Conclusion #
Au final, la meilleure solution est pour moi la v4 qui a donc :
- des valeurs par défaut ;
- pas d’héritage ;
- un index basé sur une fonction de hachage sur l’identifiant ;
- pas d’index sur le reste.
Avec un temps d’exécution de la requête d’une fraction de milliseconde, même sur un table contenant 25 millions d’entrées, c’est la connexion réseau avec la base de données qui risque de prendre le plus de temps.
Bref, PostgreSQL est très performant et je regrette absolument pas d’avoir dégagé Redis / Valkey de mes applications en développement. C’est plus de l’embêtement qu’autre chose, PostgreSQL fait très bien l’affaire, y compris pour de gros projets.