Récemment, j’ai participé à un meetup dans les locaux d’un grand hébergeur français connu pour son manque de support de l’IPv6. Forcément, je n’ai pas pu résister à l’idée d’aller troller discuter avec notre hôte sur ce sujet. C’est alors que, de la manière la plus innocente du monde, ce dernier m’a demandé pourquoi est-ce que j’ai besoin de l’IPv6 alors que l’IPv4 fonctionne très bien. Du coup, vu qu’il existe encore de nombreuses personnes qui, comme lui, pensent que l’IPv6 n’est rien de plus qu’un caprice de geek, je publie ici les raisons qui, personnellement, me marquent le plus.
Sur mes serveurs #
HTTP(S) #
Normalement, toute personne ayant un minimum de connaissances en informatique sait qu’une même machine peut héberger plusieurs sites web. Dans un monde dominé par l’IPv4, cette machine dispose en général d’une adresse IP unique. Lorsqu’un client se connecte à la machine, il va lui annoncer le nom de domaine qu’il veut joindre afin que le serveur web puisse lui envoyer le bon site. En HTTP simple ça ne pose pas de problème, mais en HTTPS la requête contenant le nom de domaine (en-tête Host) est en capsulée dans une connexion TLS, donc chiffrée. C’est là que les choses se corsent. Pour établir une connexion chiffrée, il faut que le serveur présente un certificat de sécurité valide pour le nom de domaine demandé. Mais lorsqu’un client se connecte, le serveur doit présenter le certificat du domaine alors que le client ne lui communiquera le nom de domaine qu’une fois la connexion établie. Houston, nous avons un problème…
Heureusement, si de nos jours tout fonctionne c’est qu’il existe une solution. Cette dernière s’appelle SNI et est très simple : le client indique le nom de domaine qu’il souhaite joindre tout au début de la négociation TLS. Voila, le tour est joué, IPv6 ne sert a rien car nous avons contourné les limitations d’IPv4 grâce au SNI. Finalement, c’était simple. Sans doute trop simple même…
Au fait, si un client indique en SNI un nom de domaine différent de celui de l’en-tête Host, le serveur doit-il chercher à corriger cette incohérence ? Et si l’un des deux n’existe pas, il se passe quoi ? Spoiler : en général, les serveurs web cherchent toujours à retourner une ressource, quitte à en définir une par défaut s’ils ne savent pas laquelle choisir. Ce qui veux dire que parfois il est possible, en connaissant un domaine, de forcer le serveur web à vous révéler un autre domaine ou service hébergé derrière la même adresse IP. Niveau respect de la vie privée on a vu mieux.
Au moins, avec IPv6, il est possible d’attribuer une adresse IP par service sur la machine. Ainsi, plus besoin de tenir compte du SNI ni du contenu de l’en-tête Host. Si le serveur est contacté sur cette IP il n’y qu’une seule ressource à servir, aussi bien au niveau du certificat de sécurité que du service web, point final. Simple, efficace et sécurisé.
Virtualisation #
Pour plus de sécurité, l’on a souvent envie d’isoler certains services d’une machine dans une machine virtuelle ou un conteneur dédié. Ceci permet qu’en cas de compromission du service, l’attaquant ne puisse pas compromettre le reste du système. Une très bonne illustration de ce mode de fonctionnement est la distribution GNU/Linux Proxmox VE qui est intégralement dédiée à la virtualisation.
Mais lorsqu’une machine hôte n’a qu’une seule adresse IPv4, les machines virtuelles sont alors reliées à l’extérieur à l’aide du NAT. Lorsque ces machines sont des clients ça passe, mais vu que nous sommes dans une logique de serveur, d’un seul coup, c’est plus complexe. Il faut alors, sur l’hôte, mettre en place une redirection de ports afin de faire suivre les connexions sur un port donné vers la VM. Ça fonctionne bien jusqu’au moment où une VM doit accepter des connexions sur le même port qu’une autre VM ou que l’hôte. Typiquement, si deux VM présentent un service web joignable en HTTP ou HTTPS, j’ai un problème. Je dois alors mettre en place un reverse-proxy web sur l’hôte qui, en fonction du SNI et/ou de l’en-tête Host, redirigera vers la bonne VM. Ce reverse-proxy web peut également être mis en place sur une nouvelle VM sur qui l’hôte redirige tout le trafic entrant sur les ports HTTP et HTTPS.
Encore, avec HTTP(S) ça passe parce que l’en-tête Host fait partie intégrante du protocole HTTP et que tous les navigateurs web moderne supportent le SNI. Mais comment fait-on si l’on a un protocole qui n’a aucune notion de nom de domaine et ne peut donc pas avoir de reverse-proxy ? Pas besoin d’aller chercher des exemples exotiques, en voici deux de la vie courante : DNS et SSH. Bon courage si vous souhaitez avoir deux serveurs DNS différents derrière une même adresse IP. Pour SSH il y a moyen de faire semblant en utilisant un port différent ou en se basant sur le nom d’utilisateur, voir sa clé publique, pour transférer au bon serveur, mais c’est fastidieux et très restrictif.
Au moins, avec IPv6, je peux attribuer une adresse IP différente par machine virtuelle, c’est quand même bien plus simple. Et du coup je peux avoir deux serveurs DNS (et SSH) différents vu qu’ils ont chacun leur propre adresse IP.
Et même sans virtualisation #
Il me semble quand même utile de préciser que tout ce que j’ai dit au sujet de la virtualisation est également valable sans avoir de VM ni de conteneur. Par exemple, pour reprendre l’exemple de SSH, ma machine dispose d’un serveur qui me sert pour l’administrer, mais également d’un second serveur SSH utilisé par Gitea. Malheureusement, ne pouvant actuellement pas me passer de l’IPv4, j’ai été obligé de configurer le serveur SSH de Gitea pour écouter sur le port 2222 afin de laisser le port 22 libre mon le serveur OpenSSH permettant d’administrer ma machine.
Oui, ça fonctionne. Oui, j’ai mis le nouveau port dans mon ~/.ssh/config. Mais non ce n’est pas élégant. C’est un peu comme rafistoler des lunettes avec du ruban adhésif, vous le faite parce que vous êtes pauvre et n’avez aucun moyen de faire autrement. Si vous avez un peu d’argent vous en achetez de nouvelles et si vous avez accès à de la magie (d’IPv6 ?) vous les réparez d’un coup de baguette.
Edit: Notons que dans le cas précis de Gitea avec SSH, il possible de contourner ce problème en utilisant un seul serveur (celui du système) au lieux de deux (celui du système et celui intégré à Gitea). C’est rendu possible uniquement parce que Gitea supporte explicitement ce mode de fonctionnement, ce ne sera donc pas forcément le cas avec d’autres technologies.
Reverse-DNS #
Tout le monde connaît le principe du DNS, à partir d’un nom de domaine on récupère une information, souvent une adresse IP. Le reverse-DNS c’est à la fois la même chose à l’inverse à la fois : à partir d’une adresse IP on obtient un nom de domaine. C’est l’inverse parce que c’est le mécanisme dans l’autre sens, mais c’est totalement identique parce que l’adresse IP est « transformée » en un nom de domaine spécial qu’on interroge alors comme n’importe quel autre nom de domaine afin d’obtenir la réponse.
Si un nom de domaine pointe sur une adresse IP dont le reverse-DNS pointe vers ce même domaine, on parle alors de FCrDNS. Dans la théorie, ça devrait toujours être le cas. Malheureusement, vu les restrictions d’IPv4, beaucoup de services de domaines différents sont hébergés derrière la même adresse IP. Du coup, le FCrDNS est relativement rare.
Cet effet est plutôt indésirable dans la mesure où certains protocoles utilisent le FCrDNS pour garantir une certaines légitimité de l’interlocuteur. Un exemple célèbre est la lute contre les emails indésirables.
Je ne sais pas pour vous, mais personnellement l’idée qu’un site web situé sur un domaine utilise une adresse IP dont le reverse-DNS est un autre domaine utilisé par un serveur email, je ne trouve pas ça élégant du tout. Une fois de plus IPv6 est indispensable si l’on souhaite avoir une infrastructure propre. Un service, une adresse IP, un reverse-DNS correspondant. Point.
Tout ça en IPv4 #
Vous me répondrez très certainement que tout ce que je cite est réalisable en IPv4. Certes, c’est vrai, mais à quel prix ? Au moment où j’écris ces lignes, les principaux hébergeurs français facturent aux alentours de 2,40 € TTC par mois et par adresse IPv4 supplémentaire. Et avec des frais d’installation en sus, bien entendu.
Pour une entreprise ayant un peu de budget, ce n’est presque rien. En revanche, pour les particuliers, le coût devient vite énorme. Au bout de seulement quelques IPv4 supplémentaire l’on atteint une ou deux fois le prix du serveur lui-même. Si, sur mon serveur, j’utilisais autant d’IPv4 que d’IPv6, mes coûts mensuels augmenteraient alors de 533%, sans compter les frais de mise en service..
N’oublions pas non plus qu’avec la raréfaction des adresses IPv4 du aux fortes demandes, le prix de ces dernières ne peut qu’augmenter. Le prix ne baissera pas avant le jour où ce sera devenu inutile.
En tant que client #
Quelle est mon IP ? #
Parfois, les gens ont besoin de connaître leur adresse IP. Pour l’IPv4 c’est compliqué vu que dans l’immense majorité des cas seule la « box internet » en dispose, NAT oblige. Les ordinateurs du réseau local ont alors une adresse privée qui n’en sort pas. Du coup, les utilisateurs ont la plupart du temps recours à un service externe, souvent un site web, qui leur affiche leur adresse IP publique. Avec IPv6, on a la réponse directement sur son ordinateur.
Fini le CGNAT #
Avec la pénurie d’IPv4, beaucoup trouvent des subterfuges, souvent complexes, afin de contourner le problème. Un qui est très utilisé par les fournisseurs d’accès à internet est le CGNAT. Le principe est simple : plusieurs clients différents utilisent la même adresse IP. L’implémentation est elle, en revanche, sacrément dégueulasse. Grâce à cette abomination technologie, nos FAI peuvent dépenser de l’argent pour conserver IPv4 au lieux de dépenser de l’argent pour passer à IPv6.
Le CGNAT a l’énorme désavantage d’être incompatible avec l’hébergement de services. Si vous l’utilisez, vous pouvez abandonner l’idée d’être un serveur. Certes, l’usager lambda est (malheureusement) plus souvent uniquement un client qui consomme de la donnée. Mais pas toujours, par exemple si vous utilisez des protocoles de partage de fichiers en pair-à-pair. Stop, arrêtez de penser « activité illicite », ça n’a aucun rapport. Le pair-à-pair est énormément utilisé à des fins tout à fait autorisées, que ce soit du transfert de fichiers libres (distributions GNU/Linux, œuvres sous licences libres, etc) ou même juste pour aténuer la charge d’un serveur fournissant un contenu (principe de fonctionnement P2P de PeerTube).
Et puis, accessoirement, utiliser IPv6 au lieux du CGNAT vous évitera de vous prendre par erreur un raid de la police parce que votre voisin, utilisant la même IPv4 que vous, a téléchargé des fichiers pédopornographiques. Ne rigolez pas, c’est arrivé. D’ailleurs, cette conséquence du CGNAT n’est pas vraiment appréciée des forces de l’ordre. Ainsi, en 2017, Europol s’est insurgée contre le CGNAT et a même appelé à y mettre fin car ça gêne leurs enquêtes criminelles.
Le télétravail #
Dans beaucoup d’entités, un élément essentiel du télétravail est le VPN. Or, certains VPN ne peuvent pas fonctionner en CGNAT. C’est par exemple le cas de l’endroit où je travaille, qui n’a pas non plus déployé l’IPv6. Afin de ne pas avoir à déployer l’IPv6, le service de l’informatique interne a trouvé une solution de contournement : imposer aux personnels de demander une IPv4 full-stack à leur fournisseur d’accès à internet. C’est ce que j’ai fait, jusqu’au jour de mon déménagement où cette option a sauté et que, à cause de la pénurie d’IPv4, il n’y en avait plus une seule de disponible.
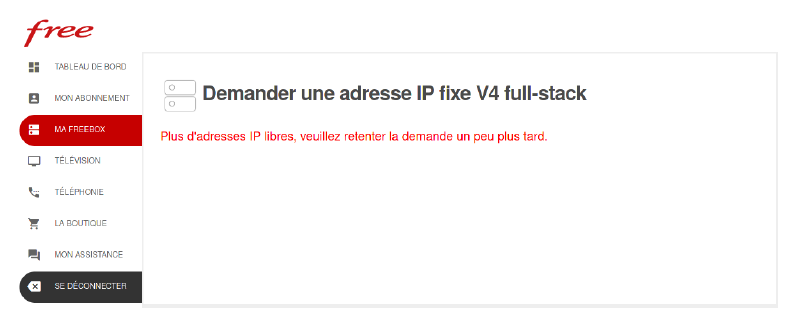
Du coup, en pleine période de pandémie, à l’heure où le mot d’ordre des autorités sanitaires est de rester chez soi, il m’est impossible de télétravailler parce que mon employeur n’a jamais pris le temps de supporter l’IPv6. Ne devant pas être le seul dans cette situation, je me dit que sur ce coup là, on met potentiellement des vies en danger.
Les fausses bonnes raisons de rester en IPv4 #
Si j’utilise une IP publique je vais me faire hacker #
Bien tenté Jean-Kévin, mais ça ne marche pas comme ça. Ce n’est pas parce qu’une adresse IP est adressable sur internet que l’on peut se connecter à la machine en question. Et oui, il est possible de mettre des pare-feux à plusieurs niveaux, en particulier sur l’élément de réseau qui relie le réseau local au réseau public (par exemple une « box internet »).
En général, ce pare-feu laisse passer les connexions sortantes et bloque les connexions entrantes. Ainsi, on peut naviguer sans qu’une personne extérieur ne puisse initier de connexion sur nos machines. Bien entendu, si une ou plusieurs machines doivent être des serveurs, on configurera le pare-feu afin de laisser passer les connexions entrantes sur les ports qui vont bien.
Le NAT est plus sécurisé #
C’est un argument souvent entendu, alors faisons un point rapide dessus bien qu’il nous faudrait détailler dans un billet dédié. Beaucoup considèrent IPv4 comme plus sécurisé grâce à l’utilisation du NAT car avoir une seule adresse IP publique évite qu’il soit possible de « cartographier » le réseau local. Avant d’exposer les arguments techniques contre cette idée reçue, détaillons un peu plus cette « menace ».
Lorsque, en tant que client, vous accédez à un service, vous transmettez à ce dernier votre adresse IP afin qu’il puisse vous renvoyer les informations demandées. Avec IPv4, c’est l’adresse IP du routeur qui est toujours utilisée, ce dernier assurant le relai sur le réseau local. Si vous avez plusieurs machines dans ce réseau local, alors le service distant ne peut pas, en se basant uniquement sur l’adresse IP publique, savoir quelle machine a effectuée la requête, d’où cette impression d’immunité à la « cartographie » du réseau local.
Malheureusement, ce n’est généralement qu’une impression car l’adresse IP n’est qu’un moyen parmi d’autres pour identifier une machine ou une personne sur le réseau. Pour illustrer ce point sans trop s’étendre dessus, je ne citerai que le cas des empreintes des navigateur internet. Les industries du ciblage en ligne déploient des monstres d’imagination pour différencier chaque personne. Mais ne soyons pas fataliste et, bien qu’ils soient actuellement en mesure de nous identifier, ne leur facilitons pas la tache avec des adresses IP fixes et uniques pour chaque machine.
Bien que le NAT soit possible avec IPv6, cette pratique n’est pas recommandée. Il nous faut donc une méthode qui nous permette, sans partage d’adresse IP, de rendre toute cartographie impossible. IPv6 nous propose ça avec la RFC 8981 (en remplacement de la RFC 4941) qui définit des extensions à l’adressage d’adresses IP via SLAAC. Cette RFC permet l’attribution d’adresses IP uniques, mais aléatoires et qui changent après un délais paramétrable. Si, sur le réseau, tout le monde change d’adresse IP publique toutes les 30 secondes, il n’est plus possible d’identifier une machine par son IP.
IPv6 c’est compliqué #
Non, c’est surtout très mal enseigné. Les programmes de la plupart des écoles d’informatique font encore actuellement une fixette sur l’IPv4 et proposent, au mieux, une légère introduction à l’IPv6. Beaucoup de ces programmes demandent même aux étudiants, sans leur expliquer à quoi ça a servit, d’apprendre par cœur les classes d’adresse IP, notion obsolète depuis un quart de siècle. Oui, vraiment un quart de siècle, c’est à dire 25 ans, donc une notion qui a cessé d’être utilisée plusieurs années avant la naissances des étudiants en question.
Ceci dit, j’admets volontiers qu’IPv6 est plus complexe qu’IPv4 de part ses nombreuses fonctionnalités. Cependant, tout au long de ce billet, nous avons vu des technologies et bidouilles crades en tous genres nécessaires pour maintenir IPv4 en service, et il en existe bien d’autres. Toutes ces « choses » n’ont plus de raison d’être avec IPv6. Il ne faut donc pas comparer uniquement la complexité de l’IPv4 face à celle de l’IPv6, mais la complexité de leurs écosystèmes respectifs. Au final ça se vaut. Je dirais même qu’IPv6 est plus simple, son point faible restant sa courbe d’apprentissage rendue difficile par le manque de formations technique de qualité.