Début 2024, Redis a annoncé changer de licence, passant ainsi de licence libre BSD 3 clauses aux licences non libres « Redis Source Available License » (RSALv2) et « Server Side Public License » (SSPLv1). Ce tournant a généré son lot de controverses et poussé à la créations de forks ainsi qu’au regain d’engouement pour les forks déjà existants. Cependant, pour un de mes projets personnel, j’ai décidé de changer mon fusil d’épaule et de partir sur PostgreSQL.
Pourquoi PostgreSQL ? #
Le point que je n’ai jamais apprécié avec le modèle de Redis est l’absence de
possibilité, dans une base de données, de pouvoir différencier plusieurs types
de données. Mon application utilisant plusieurs types de jetons se présentant
sous la forme d’UUID, j’aurai apprécié pouvoir lister chaque type afin de
pouvoir faire un état des lieux. La solution de simplicité à laquelle j’étais
venu était de préfixer le jeton par son type, le jeton CSRF
883cba9f-1ffb-433d-a49a-646e63c6a26f devant alors
csrf:883cba9f-1ffb-433d-a49a-646e63c6a26f. Ça fonctionne, mais ce n’est pas
très élégant et ça nécessite d’être pris en compte au niveau de applicatif, ce
que dont je ne suis pas friand.
Lorsque la question du remplacement de Redis s’est posée pour des questions de licences, je me suis donc également posé la question de si je souhaitais vraiment continuer sur un dérivé ayant ce même problème, et ma réponse a été que je préférais éviter.
Vouloir changer de base de données pour stocker tous mes données volatiles c’est bien, mais vers quelle solution se tourner si Redis et ses dérivés ne sont plus retenus comme choix possible ? Une réponse évidente est apparue : PostgreSQL. C’est déjà ce que j’utilise pour stocker toutes les données persistantes, donc pourquoi ne pas simplifier la stack technique et l’utiliser également pour les données volatiles ? Si sur le principe c’est effectivement une bonne idée, cela pose cependant deux problèmes : la gestion de l’expiration et les performances réputées moins bonnes.
Une question d’héritage #
Commençons par modéliser notre base de données. On considérera que nous avons besoin de deux types de jetons différents, un pour des jetons CSRF et un pour les identifiants de session, les deux étant des UUID. Une première implémentation naïve est de créer deux tables comme cela :
|
|
Ça fonctionne, mais ça fait beaucoup de répétitions et n’est donc pas optimal. Avec deux types de jetons ça passe encore, mais avec plus ça va vite devenir problématique pour la maintenance. Il y a donc mieux à faire, et pour ça nous pouvons utiliser l’héritage de tables :
|
|
Rien qu’au niveau de l’écriture c’est quand même mieux. Mais c’est surtout au
niveau de la maintenance que l’on va y gagner en facilité car, si nous pouvons
directement requêter les tables csrf_tokens et session_tokens, nous pouvons
également requêter la table tmp_values qui contient l’ensemble de nos jetons.
Purger les vielles données #
Le gros désavantage de PostgreSQL, c’est qu’il n’est pas possible
d’automatiquement supprimer les données après une période donnée comme on
l’aurait fait avec un SET key value EX ttl_in_secs dans Redis. C’est pour
cela que nous stockons une date d’expiration, qu’il faudra bien prendre en
compte lors de chaque requête.
|
|
Pour ne pas se retrouver submergés par les vieux jetons obsolètes, on prendra soin de régulièrement supprimer ceux qui sont périmés. Et grâce à l’héritage des tables, on a une seule requête à lancer :
DELETE FROM tmp_values WHERE expire_at < NOW();En général, on aura tendance à utiliser cette requête sous la forme d’une
procédure stockée régulièrement lancée à l’aide de l’extension pg_cron, mais
rien ne vous empêche de faire comme bon vous semble.
Et les performances dans tout ça ? #
S’il y a bien un avantage indéniable que l’on ne peut pas enlever à Redis, c’est bien sa rapidité. Ceci dit, posons nous deux questions :
- A-t-on réellement besoin de performances au top ?
- Peut-on tout de même s’en approcher en utilisant PostgreSQL ?
L’immense majorité des application n’ont pas besoin des performances exceptionnelles de Redis. Pour les GAFAM et certaines applications à hautes performances d’accord, mais ce sont des exceptions particulières où il y a des ingénieurs dédiés à ce genre de problématiques. Au risque de vous décevoir, la dure réalité des choses est que si vous lisez ces lignes vous ne faites probablement pas partit de ces exceptions, et moi non plus d’ailleurs.
Ceci dit, faut-il pour autant sacrifier les performances sur l’autel de la simplicité de la stack technique ? Pas nécessairement. Si Redis tire principalement ses performances de l’absence de stockage persistant des données, pourrait-on faire de même avec PostgreSQL ?
Vous serez sans doute surpris, mais la réponse est oui. Lorsque l’on créé une table, il est possible de lui passer l’attribut UNLOGGED qui empêche l’écriture des données dans les journaux de transactions. Ceci augmente considérablement leur accès en lecture, mais empêche leur récupération en cas de crash ainsi que la réplication sur d’autres serveurs.
|
|
Si l’on a une base de données non répliquée, on obtient alors des performances beaucoup plus proches de celles de Redis, sans toutefois les égaler. Si PostgreSQL est sur la même machine physique que l’application on est vraiment proche des performances de Redis, mais si vous devez passer par le réseau, tout de suite ça sera sans doute différent. Cependant, c’est déjà largement suffisant pour l’immense majorité des applications.
Edit : vu la mise en cause ci-dessous de la capacité de PostgreSQL à gérer plus qu’un petit projet personnel, j’ai fait un test.
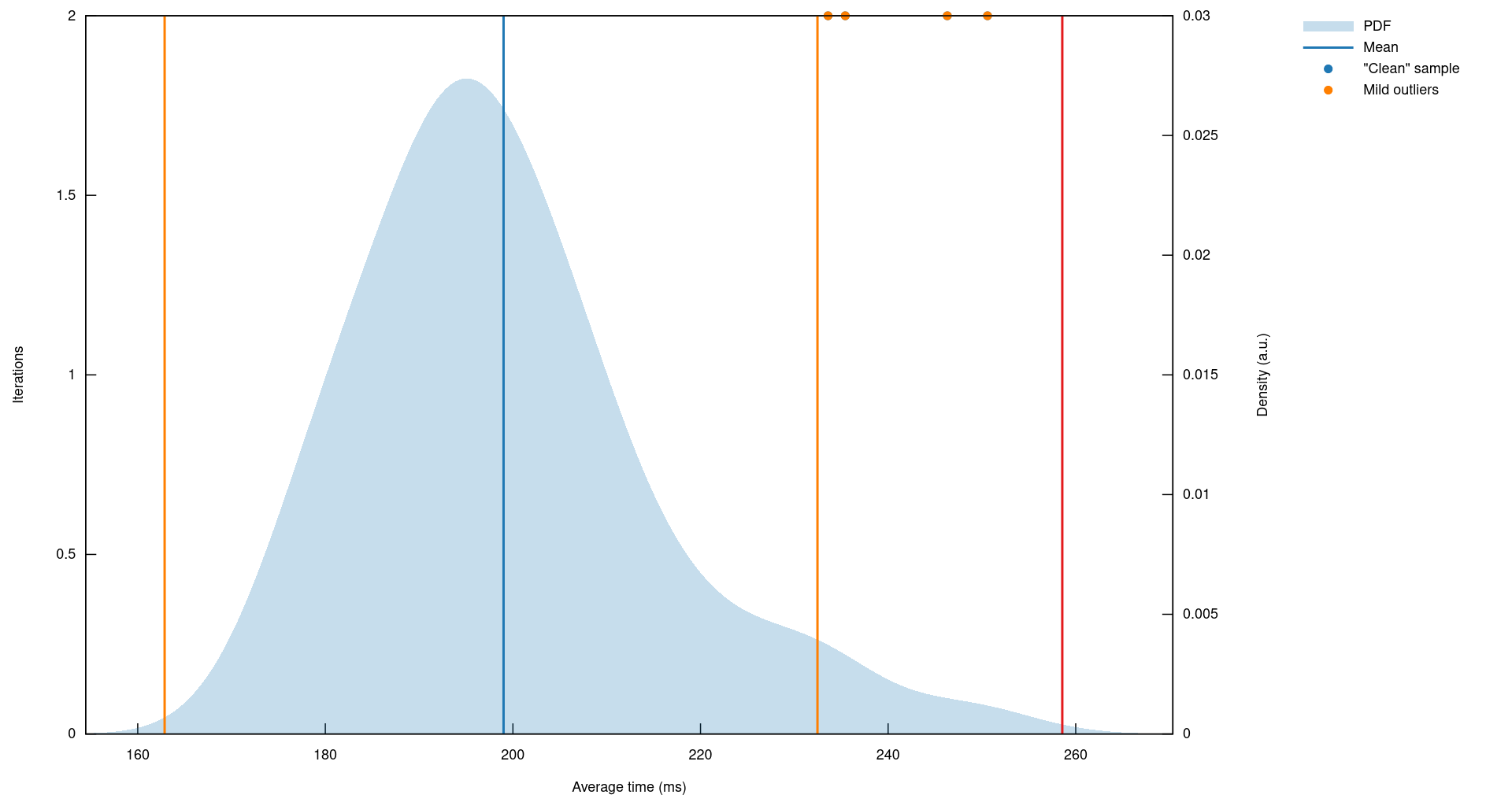
Pour voir si ça tenait, j’ai réutilisé les tables précédentes et j’y ai inséré un million d’entrées dans chaque. Vous voyez ce que ça fait déjà un million Larmina ? J’ai utilisé des UUIDv7 pour les jetons CSRF et UUIDv4 pour les jetons de session. Niveau bloated on est pas mal comme ça. J’ai benchmarké la lecture de 2000 jetons existants et 500 jetons inexistants dans chaque table. Et bien pour exécuter ces 5000 requêtes on est dans les 200 millisecondes.
Redis fait mieux ? C’est bien, cool story bro, mais en vrai on s’en fiche un peu. On gère carrément bien plus que « 3 gus dans un garage » avec un PostgreSQL et on a rarement besoin de plus performant. Il faut arrêter de vouloir croire que tout ce qui n’est pas fusée n’est pas capable d’aller suffisamment vite.
Conclusion #
Personnellement, je suis assez convaincu par ce modèle. Une stack technique plus simple et des données mieux rangée, il n’en fallait pas plus pour me faire supprimer Redis au profit de PostgreSQL. Tout ça au prix de quelques millisecondes par requête et de l’impossibilité de répliquer les données volatiles. Et même si j’avais vraiment besoin de la réplication, le coût final ne serait que de quelques dizaines de millisecondes par requête.